EScience Seminar 2009/EScience-Seminar Repository Systems
Venue[edit]
Date[edit]
25/26 June 2009
Responsible for content[edit]
Malte Dreyer, Andreas Gros, (MPDL), Stefan Heinzel (RZG), Peter Wittenburg, Daan Broeder (MPI for Psycholinguistics), Frank Toussaint, Michael Lautenschlager (MPI for Meteorology)
Introduction[edit]
The second MPG eScience seminar of 2009 is devoted to one of the big challenges for research institutes: how to guarantee persistence and continuous access to its records to all interested and authorized researchers. Therefore, each institute needs to have a strategy of how to manage the increasing amounts and complexity of data, how to guarantee online access to it and how to replicate the data for preservation purposes. The term "digital repositories" seems to properly describe the layer of functionality that we want. JISC defines the term in the following words [1]: "Repositories are important for universities and colleges in helping to capture, manage, and share institutional assets as a part of their information strategy. A digital repository can hold a wide range of materials for a variety of purposes and users. It can support learning, research and administrative processes."
The concept "Digital Repository" is not new of course, although its meaning changed rapidly due to the new requirements caused mainly by the increasing amount and complexity of data, the Internet and the awareness of long-term accessibility. Within the MPG it was Friedrich Hertweck [2] from RZG (Computer Centre in Garching) who created AMOS (Advanced Multi user Operating System) in the 70-ies. AMOS [3] was an excellent piece of software, which allowed scientists in Plasma Physics (amongst others) to store and retrieve their large data volumes, and it turned out to be an island of stability for many years. Natural sciences now need to maintain repositories that cover petabytes of data, which in general is highly structured. But also in the humanities we are now close to maintaining hundreds of terabytes where often the problem is not the sheer amount, but the inherent complexity of the data sets.
Since a few years the concept of "digital repositories" is being discussed in a number of different contexts. A recent study from the DRIVER project [4], covering 114 digital repositories, revealed that most institutes associate with this term repositories for publications. More than 80% of these repositories contain journal articles and other types of publications, only about 10 % also store primary data sets and common data types such as audio and video recordings. This is fully in line with the experiences in the European CLARIN project [5], which wants to build a network of centers functioning as the backbone for offering persistent access to language resources and services. About 80% of the potential centers are busy restructuring their repository to fulfill the new requirements. From these two results we can conclude
- that researchers are used to store ePublications in proper repositories and associate them with proper metadata for example to support discovery and
- that researchers are not used to store their research data in such ways that other researchers can easily access them.
It seems that in general researchers still use idiosyncratic methods to store their data, that they tend to structure it by minimalistic solutions, such as file names and directory structures, and that long-term accessibility was/is not an issue of primary concern. For an increasing number of researchers, in particular when they are participating in international data driven collaborations (e.g. genomics or climate), it becomes increasingly obvious, however, that they need to change their behavior.
This eScience seminar will therefore focus on repository solutions for research data, be it primary data generated by some types of sensors or secondary data that is generated by researchers to allow interpretations. The field of primary and in particular secondary data is characterized by an extreme heterogeneity of data types, formats, and implicit or explicit semantics, making it a difficult field for abstractions. This is different from ePublications where the data types and formats are widely standardized, where metadata characterization has a long history and where the semantics of the content can be interpreted by the reading researcher.
Views on Digital Repositories[edit]
Much has been written about digital repositories during the last years. We would like to cite three initiatives without claiming being comprehensive (see below). Important other initiatives have thought about repositories and layers of abstractions as well, such as FEDORA [6] or OAI-ORE [7].
DELOS Digital Library[edit]
The DELOS Digital Library project [8] presented a careful analysis of a number of aspects of "Digital Libraries" which can be transformed to digital repositories. They present a summary of the main points of their manifesto [9], which we simply include here. As a consequence of this manifesto they derive an abstract reference model. There is no clear separation between Digital Libraries and Digital Repositories, but it can be stated that a proper Digital Library model will include a proper Digital Repository as its core.
The Digital Library Manifesto in Brief
It is commonly understood that the Digital Library universe is a complex and multifaceted domain that cannot be captured by a single definition. The Manifesto [10] organizes the pieces constituting the puzzle into a single framework [1].
![[1]](http://www.dlib.org/dlib/march07/castelli/castelli-fig1.jpg){kind=link}
In particular, it identifies the three different types of systems operating in the Digital Library universe, i.e.
- the Digital Library (DL) – the final ‘system’ actually perceived by the end-users as being the digital library;
- the Digital Library System (DLS) – the deployed and running software system that implements the DL facilities; and
- the Digital Library Management System (DLMS) – the generic software system that supports the production and administration of DLSs and the integration of additional software offering more refined, specialized or advanced facilities.
The Manifesto also organizes the Digital Library universe into domains
- The Resource Domain captures generic characteristics that are common to the other specialized domains. Building on this, the model introduces six orthogonal and complementary domains that together strongly characterize the Digital Library universe and capture its specificities with respect to generic information systems. These specialized domains are:
- Content – represents the information made available;
- User – represents the actors interacting with the system;
- Functionality – represents the facilities supported;
- Policy – represents the rules and conditions, including digital rights, governing the operation;
- Quality – represents the aspects needed to consider digital library systems from a quality point of view;
- Architecture – represents the physical software (and hardware) constituents concretely realizing the whole.
Another contribution of the Manifesto is recognizing the existence of various players acting in the DL universe and cooperating in the operation of the whole. In particular,
- The DL End-Users are the ultimate clients the Digital Library is going to serve.
- The DL Designers are the organizers and orchestrators of the Digital Library from the application point of view.
- The DL System Administrators are the organizers and orchestrators from the physical point of view.
- The DL Application Developers are the implementers of the software parts needed to realize the Digital Library.
Further, it states that there is the need for modeling focused views. The ultimate goal of the whole reference model activity is to clarify the Digital Library universe to the different actors by tailoring the representation to their specific needs. The three systems organize the universe in concentric layers that are revealed to interested players only. Meanwhile, the six domains constitute the complementary perspectives from which interested players are allowed to see each layer. Thus, the framework is potentially complex because it aims at accommodating all the various needs. However, it is highly modular and can therefore be easily adapted to capture the needs arising in specific application contexts.
Finally, the Manifesto gives reason for proceeding with different levels of abstraction while laying down the complete framework. These different levels of abstraction, which lead conceptually from the modeling to the implementation, are captured in this Figure where the core role of the Reference Model is illustrated; all the other elements constituting the envisaged DL development methodology chain start from here. It drives the definition of any Reference Architecture that proposes an optimal architectural pattern for a specific class of 9 It is still under discussion whether two other players should be added to this list, namely Institutions and Industries. By Institutions are meant organizations, either concrete or virtual, having the important role of forming the Digital Library. By Industries are meant the institutions performing economic activities concerned with the Digital Library, by providing either the software or the service.
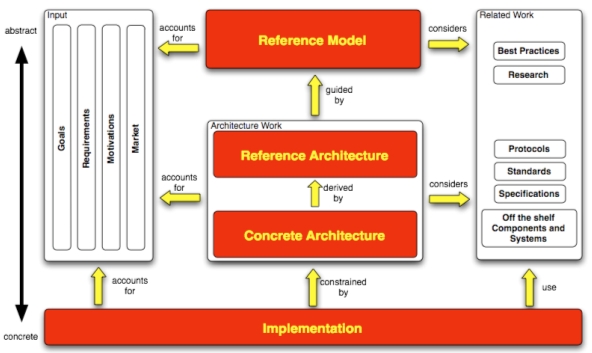{kind=link}
CLARIN Research Infrastructure[edit]
CLARIN is such an ESFRI initiative and as such made some statement and established some criteria for centers to participate. It does not make statements about the internal solution being adopted because many different approaches of how to set up a stable repository have been selected dependent on local or national considerations. In addition to describing the terms "digital repositories" and "digital archives" as a repository with a long-term strategy, CLARIN touches a few topics that are not discussed so frequently:
- It introduces the term "Live Archives" to denote the fact that scientific data -- except for the primary recordings -- is subject of continuous changes and enrichments and that every repository needs to cope with these phenomena but nevertheless has to be able to dereference a unique identifier to a specific resource, the content of which may not change.
- It refers to the OAIS model [11] as a general reference model and to initiatives such as "Data Seal of Approval" [12], DRAMBORA [13] and TRAC [14] as ways to assess the quality and appropriateness of the repository/archive setup.
- It refers to container formats that bundle content, metadata descriptions and relations, which can be used as exchange formats, but also can be used to structure repositories. It also makes the point that encapsulation is problematic with respect to long-term archiving.
With respect to the local solutions it mentions a wide variety of solutions that can and are being applied, such as file systems with a layer of related metadata descriptions and additional functionality; e.g. LAMUS [15] as a light weight example for such a repository, relational databases that contain data and metadata in sets of related tables, XML databases mainly useful to store all types of XML-structured resources, content management systems that do not depend on a specific data model, solutions such as FEDORA that are based on an object model and come along with an API to manipulate the objects, eSciDoc as an example for a solution that makes use of the FEDORA object model in its core, SRB [16] and recently iRODS [17] as a solution that from the beginning integrated ideas from the grid and federated repositories, D-Space [18] and ePrints [19] as full-blown solutions mainly directed towards publications, cloud-like solutions (Google, Flickr, Amazon, etc.) that offer storage and require the users to associate terms with resources (social tagging).
As indicated, CLARIN does not want to make statements about the internal solution chosen, but established a number of criteria that need to be ensured:
- Centers need to offer useful services to the CLARIN community, which can be a mixture of metadata descriptions, data resources, processing components and/or infrastructure services.
- Centers need to agree with the basic CLARIN principles:
- independence, i.e. free choice of internal organization of service
- service, i.e. explicit statements about services, their duration and their quality
- consistency, i.e. guarantee to deliver the same content for the same identifier which includes the usage of persistent identifiers
- interoperability, i.e. adhere to CLARIN protocols and agreements such as the joint standard on component-based metadata descriptions and the usage of agreed concepts registered in the ISOcat "concept" registry [20]
- responsibility; i.e. commitment to take over responsibility for its services
- CLARIN will expect that if a service once offered to CLARIN will be stopped, the service will be transferred to another center to guarantee continuity for the user community.
- Centers need to adhere to all security guidelines, join the national identity federation where available and be ready to join the CLARIN service provider federation.
- Repositories in CLARIN should have a proper and clearly specified repository system and participate in a quality self-assessment procedure as proposed by DANS or others (see above).
- Each center needs to make clear statements about their business model and their treatment of legal and ethical issues.
Requirements for Repository Systems[edit]
From the various initiatives dealing with repositories we can finally list a number of requirements that a repository system obviously needs to fulfill. In terms of an abstract information model, the technical requirements define a set of functions that can be called from other applications.
- Repositories need to be trustworthy and therefore it is required that their repository system supports suitable security and access permission mechanisms.
- Repository systems need to be integrated into quality assessment procedures and therefore need to provide access statistics.
- Repository systems need to offer structuring options that support managing large amounts of related resources where the incarnation of a resource is its rich metadata description that adheres to a community wide accepted standard.
- Researchers increasingly often use individual resources in various collections for various purposes, i.e. the repository system needs to support mechanisms to build arbitrary collections of "atomic" resources and to identify such collections by metadata descriptions for citation and other purposes.
- Repository systems need to support the "live archives" principle, i.e. they need to cope with extensions of existing resources without changing stored objects (thus versioning) and with additional resources at various dimensions, including enrichments such as commentary and relations between resources.
- Each resource (version) needs to be uniquely identified by a persistent identifier and information enabling authenticity checks, so that a user – when accessing a resource with a certain identifier – is ensured that he will get the same resource.
- Repository systems need to support resource replications within trusted federations to support long-term preservation and access optimization. All instances share the same identity, i.e. a persistent identifier would typically indicate all existing copies.
- Repository systems need to support resource curation by communities, which is needed because of the continuing changes of formats and encoding principles.
- Repository systems need to have mechanisms to guarantee a high availability and persistence so that researchers can rely on the services they offer. These services need to be explicitly documented and APIs need to be available for program access.
- Repository systems need to have facilities to ensure format and encoding consistency based on explicit specifications.
- Repository systems will increasingly often be embedded in federations and therefore need to ensure interoperability at various levels to allow users for example to build virtual collections.
- Since repository systems often need to support long-term interpretability, resource encapsulation mechanisms for unreadable and proprietary formats need to be carefully documented and should be avoided whenever possible. Software will have a limited life-time and data survival will depend also on the maintenance costs.
In addition, it is of great importance to have a stable and cost efficient maintenance model for all software that is used in addition to the standard software components.
Programme and contributions[edit]
| Day 1 | Topic | Speaker |
| 10:00 | Introduction & Requirements (slides, 1 MB) | Peter Wittenburg, Stefan Heinzel |
| 10.45 | Necessity of Repositories and Roles (slides, 8 MB) | Wouter Spek (APA) |
| 11:30 | ESFRI Requirements (slides, 4 MB) | Dany Vandromme (Renater) |
| 12:15 | Discussion | |
| 12:30 | Lunch | |
| 13:30 | Data Models and Abstraction Layers (slides, 0.3 MB) | Carlo Meghini (ISTI) |
| 14:30 | Repository Systems - Solutions from Microsoft (slides, 5.8 MB) | Savas Parastatidis (Microsoft) |
| 15:30 | Coffee break | |
| 16.00 | MPI: Architecture at the MPI f. Meteorology (slides, 3.3 MB) | Frank Toussaint (Meteorology) |
| 16.30 | MPI: Architecture at the MPI f. Psycholinguistics (slides, 1.4 MB) | Daan Broeder (Psycholinguistics) |
| 17.00 | MPI: Infrastructure at the MPI f. Human Cognitive and Brain Sciences (slides, 0.9 MB) | Roberto Cozatl (Human Cognitive and Brain Sciences) |
| 17.30 | MPI: Long-term archiving of scientific data for publications | Holger Bartels (Biophysical Chemistry) |
| 18:00 | End of Day 1 | |
| 19:00 | Dinner | |
| Day 2 | Topic | Speaker |
| 9:00 | Abstractions, Functionality and Services in eSciDoc (slides, 9.4 MB) | Malte Dreyer (MPDL) |
| 9.45 | Repositories,Federation and iRODS (slides, 0.3 MB) | Adil Hasan (University of Liverpool) |
| 10:30 | Coffee break | |
| 11:00 | MPI: Requirements for Repository Systems (slides, 5.5 MB) | Ulrich Degenhardt (Dynamics and Self-Organization) |
| 11:45 | Long-term Requirements and Quality Assessment (slides, 3.4 MB) | Henk Harmsen (DANS) |
| 12:15 | Lunch | |
| 13.15 | Trust, Accessibility, Business Models, Costs (slides, 1 MB) | Peter Wittenburg (Psycholinguistics) |
| 13:45 | Wrap-Up, Discussion | Stefan Heinzel, Andreas Gros, Frank Toussaint |
| 16:00 | The End | |
Registration[edit]
Registration is open at: http://escience.mpg.de/registration_en.html
Video feed[edit]
We will feed the talks via a H.323 video-conferencing system. The corresponding E.164 MCU-Number is:
004910097918024.
For some documentation about the system, please visit: https://www.vc.dfn.de/en/dokumentation/videoconferencing-mit-h323/zugangswege/h323.html. This is the first time we try something like this, so please bear with us. As usual you will be able to download the slides a couple of days after the seminar.
References[edit]
- ↑ http://www.jisc.ac.uk/whatwedo/programmes/digitalrepositories2005/repositories_conference.aspx
- ↑ http://www.ipp.mpg.de/ippcms/de/presse/archiv/10_98_pi.html
- ↑ http://de.wikipedia.org/wiki/Rechenzentrum_Garching
- ↑ http://www.driver-repository.eu/
- ↑ http://www.clarin.eu/
- ↑ http://www.fedora-commons.org/
- ↑ http://www.openarchives.org/ore/
- ↑ http://www.delos.info/
- ↑ http://www.delos.info/index.php?option=com_content&task=view&id=345&Itemid=#docs
- ↑ http://www.dlib.org/dlib/march07/castelli/03castelli.html
- ↑ http://nost.gsfc.nasa.gov/isoas/
- ↑ http://www.dans.knaw.nl/en/data_deponeren/dans_keurmerk/
- ↑ http://www.repositoryaudit.eu/
- ↑ http://www.crl.edu/content.asp?l1=13&l2=58&l3=162&l4=91
- ↑ http://www.mpi.nl/lamus
- ↑ http://www.sdsc.edu/us/resources/srb/
- ↑ https://www.irods.org/
- ↑ http://dspace.mit.edu/
- ↑ http://www.eprints.org/
- ↑ http://www.isocat.org/